【本文原载于PKU-AIIT数字创意实验室公众号2026年2月13日推文】
北京大学信息技术高等研究院数字创意实验室(PKU AIIT DCL) 倾力打造《美美与共:2026 AI赋能文化产业发展报告》,现已正式面向公众免费发布。
报告由《AI创意业态透视》与《AI工具全景指南》两部分构成,共计300余页,分别从理论框架与实践工具切入,为行业提供体系化参考。文末附完整报告获取方式。
本文摘选自《AI创意业态透视》,重点聚焦于2023年以来全球AIGC的发展脉络,以及AI在文化产业各种领域带来的重大变革。以下为精华内容呈现:
回顾AIGC的发展历程,我们看到的是一条指数级跃升的技术曲线。这不仅仅是参数量的堆叠,更是模型架构、训练方法与推理能力的质变。
2023-2024
大模型的“百模大战”与多模态突破
以OpenAI发布的GPT-4 为标志7,2023年确立了Transformer架构在自然语言处理领域的统治地位。
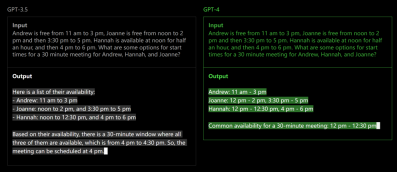
GPT-4 相较于GPT-3.5
展示出更强的推理能力
随后,Anthropic推出的Claude系列,以其“宪法 AI”(Constitutional AI)的安全性和超长上下文窗口 (Context Window),在长文本分析与文学创作领域占据一席之地。

Google 的 Gemini 系列则展示了原生多模态 (Native Multimodal)的潜力,打通了文本、图像与视频的理解壁垒。

这一阶段的特征是“深度神经网络快速发展”。各大科技巨头竞相通过增加参数量(Scaling Law)来提升模型能力,导致训练成本高企,最终仅头部企业能充分受益。
2025年是人工智能从“快思考”转向“慢思考”的分水岭。
随着 DeepSeek-R1 等推理模型(Reasoning Models)的发布,AI 开始展现出类似人类“系统2”的慢思考能力。这种能力对于文化产业至关重要——它意味着AI不再只是通过概率“猜”下一个字,而是开始“推演”剧情的逻辑闭环、计算游戏的数值平衡
1.2.2 推理能力“外溢”至多模态
(Visual Reasoning)
学术界正在尝试将这种“严密的逻辑推理”引入视觉生成领域。以往的AI绘图往往“手还是画不对”,正是因为缺乏对物理世界的逻辑理解。2024—2025年的技术突破,正是为了解决这个问题:
统一多模态生成的新范式(Liquid模型): 2024年12月,字节跳动等机构提出的Liquid模型,首次尝试将“视觉”和“语言”完全统一。它让AI像理解代码一样理解图像token。这意味着,AI在生成视频时,能更好地理解物体之间的互动逻辑,减少了画面的崩坏和干扰。
视觉自回归建模(VAR): 获得NeurIPS 2024 最佳论文奖的VAR模型,提出了一种“从整体到细节”的生成方式。这证明了GPT式的自回归模型在图像生成上也能超越扩散模型,为视觉模型提供了Scale Up(做大做强)的理论基础。
扩散模型与自回归的融合(DiffusionVL): 2025年1月,华中科技大学提出的DiffusionVL,证明了可以将推理能力强的自回归模型,通过微调转换为视觉生成模型。这实现了性能与效率的双赢——既有推理模型的逻辑脑,又有扩散模型的艺术手。
DeepSeek-R1通过混合专家 (MoE)架构,将成本压缩到OpenAI同类模型的几分之一。这种算力普惠使得中小微文创企业也能用得起顶级模型,推动了AIGC在剧本、NPC、音乐等领域的快速落地。
为了更直观地展示2023-2025年间AIGC技术的关键演进,下表梳理了代表性模型/事件及其关键技术特征和对文化产业的影响。

在2023年至2024年间,中国AI产业一度面临算力芯片受限的严峻挑战。然而,这种外部压力倒逼出了极致的算法创新。以杭州深度求索(DeepSeek)为代表的中国AI公司,走出了另一条技术路径。
DeepSeek在2025年初发布的R1模型及V3版本,不仅在响应方式和推理能力上对标 OpenAI的o1系列,但更重要的是其极致的成本控制。通过混合专家架构 (Mixture-of-Experts,MoE)和多头潜在注意力机制 (MLA),DeepSeek将训练成本和推理成本压缩到了竞争对手的几分之一 。
开源生态的胜利:DeepSeek采取了类似Meta Llama的开源策略(MIT协议),这使得大量中国文化科技公司能够基于其基座模型进行垂直领域的微调(Fine-tuning)。例如,阅文集团可以基于此训练懂“网文梗”的写作模型,游戏公司可以训练懂“金庸武侠”的NPC对话模型。
打破算力封锁:尽管面临英伟达高端芯片(H100/H800)的出口管制,DeepSeek通过算法优化和软硬件协同,证明了在受限算力下依然可以训练出世界级模型。这一成就极大地提振了中国文化产业在智能化转型中的“技术自信”。
除了DeepSeek,2025年的中国AI版图呈现出百花齐放的态势:


这一自主可控的模型生态,为2026年中国文化产业的全面增长奠定了坚实的“数字底座”。
2023—2025年,国际学术界在生成式AI领域取得了一系列突破性进展,为AIGC技术的演进提供了坚实的理论基础和实验支撑。以下精选了部分具有代表性的研究成果:
DiffusionVL(2025):华中科技大学提出的将任意自回归模型转换为扩散视觉语言模型的方法,通过简单的扩散微调实现了性能的飞跃,在多模态基准上达到SOTA水平。
Scaling Diffusion Language Models(2024):Shansan Gong等人的研究系统探讨了扩散语言模型的Scaling特性,发现在数据受限条件下,扩散 模型优于自回归模型,为资源受限环境提供了新的生成范式。
Liquid(2024):字节跳动等联合提出的统一多模态生成器,首次将语言模型作为多模态生成器,通过共享特征空间实现视觉与语言的无缝融合,显著降低了模型复杂度并提高了性能。
FoundationVision/VAR(2024): 获得NeurIPS2024最佳论文奖的视觉自回归建模方法,重新定义了图像生成的自回归学习方式,首次证明了GPT风格自回归模型在图像生成上可以超越扩散模型,并发现了视觉生成中的 Scaling Laws。
Masked Diffusion Models(2024):Liu 等人的研究系统比较了扩散模型与自回归模型在数据受限条件下的性能,表明扩散模型在图像生成任务上具有显著优势,为在有限数据条件下部署AIGC提供了新思路。
此外,还有许多研究在AIGC的不同方向上取得了进展,例如Efficient Training of Language Models to Fill in the Middle (2022)通过在模型中插入“填充”token来加速训练,提高了模型的推理效率。这些研究成果共同推动了AIGC 技术的边界不断扩展。
综上所述,2023—2025年是AIGC技术从“量变”到“质变”的关键时期。在全球范围内,以OpenAI、Anthropic、Google 等为代表的科技巨头推动了多模态大模型的发展;在中国,以DeepSeek为代表的团队通过算法创新和开源生态,打破了算力封锁,实现了低成本高性能模型的突破。与此同时,国际学术界在扩散模型、自回归模型、统一多模态生成等领域的研究成果,为 AIGC技术的演进提供了坚实的理论基础和实验支撑。标志着AIGC正式从“玩具”变成了文化产业的“生产工具”。

北京大学信息技术高等研究院数字创意实验室(PKU DCL)是设立在北京大学信息技术高等研究院数字经济研究中心的重点实验室,以前沿交叉为特色、以理论实践为导向。实验室由国家“万人计划”哲社科领军人才、北京大学艺术学院教授、北京大学文化产业研究院院长向勇担任主任。
本报告已经面向公众免费发布。若您希望获取完整PDF版本,请按以下步骤操作:
关注本公众号
在首页对话框回复关键词“2026AI赋能文化产业报告”,系统自动推送百度网盘下载链接

